数据抽象和类 Ⅲ
动态内存和类
C/C++ 内存空间分布
内存分区
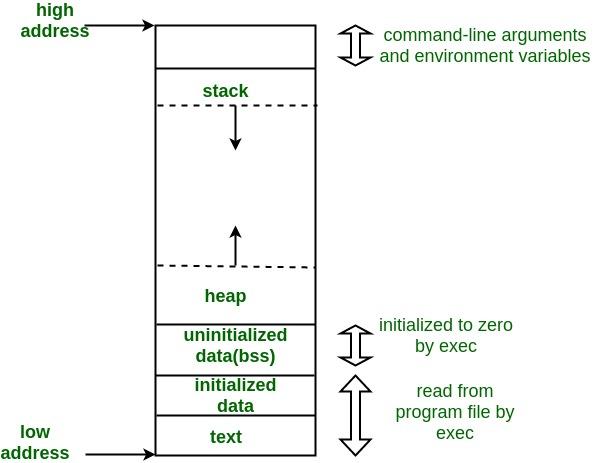
Text–只读、共享,操作系统管理是对象文件或内存中程序的一部分,其中包含可执行指令(函数实现,库实现,字符串等资源)。文本段在堆栈的下面,是防止堆栈溢出覆盖它。
通常代码段是共享的,对于经常执行的程序,只有一个副本需要存储在内存中;代码段是只读的,以防止程序以外修改指令。
Initialized data- 通常称为数据段,是程序的虚拟地址空间的一部分,它包含程序员初始化的全局变量和静态变量以及常量,可以进一步划分为只读区域和读写区域。
Unintialized data–内核初始化为0- 通常称为
bss段
- 通常称为
Heap–程序员管理堆是动态内存分配通常发生的部分(动态变量(对象))
内存分配由低到高,分配方式类似于数据结构的链表。堆区域从
BSS段的末尾开始,并从那里逐渐增加到更大的地址。堆是由程序员自己分配的,或程序结束后由操作系统自动回收。堆区域由所有共享库和进程中动态加载的模块共享。(
malloc和new从堆区分配内存)
Stack–编译器分配管理栈是存放自动变量,以及函数调用时保存的信息的部分(自动变量(对象)、函数参数)
每当进行函数调用时,函数的实参和返回地址以及调用者的上下文环境会被存放在栈中;栈区由编译器自动分配,从高地址向低地址扩展。
在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的
C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。1
2char *s1 = "Literal"; // 文字在代码区,仅分配了字符指针
// s1[0] = 'I'; // Segmentation fault1
char s2[] = "Initial Literal"; // 分配数组空间
1
ptr_type* ptr_name = &((ptr_type){2,3}); // 分配结构空间及指针
堆 栈 的性能区别
写入方面:入栈比在堆上分配内存要快,因为入栈时操作系统无需分配新的空间,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备。
读取方面:得益于 CPU 高速缓存,使得处理器可以减少对内存的访问,高速缓存和内存的访问速度差异在 10 倍以上!栈数据往往可以直接存储在 CPU 高速缓存中,而堆数据只能存储在内存中。访问堆上的数据比访问栈上的数据慢,因为必须先访问栈再通过栈上的指针来访问内存。
因此,处理器处理和分配在栈上数据会比在堆上的数据更加高效。
内存分区的意义
不同区域存放的数据,赋予不同的生命周期,给编程更大的灵活性。
C 动态变量(对象)管理
正确使用堆空间
- 必须使用
#include <stdlib.h> void* malloc(size_t) // 申请空间void free(void*) // 释放空间- 申请的空间必须释放,否则会导致内存泄漏
free后再使用或释放指针,行为不可预测。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23typedef struct { int x; int y; } Point;
int main(void) {
// 分配变量或一维可变数组
Point* p1 = malloc(sizeof(Point) * 10);
// 分配二维数组(n,m是常数)
point (*p2)[2][3] = malloc(sizeof(Point) * 6);
// 分配数组的数组
int n = 2;
int m = 3;
Point **p3 = malloc(sizeof(Point *) * n);
for (size_t i = 0; i < n; i++) {
p3[i] = malloc(sizeof(Point) * m);
}
// do somesthing
free(p1);
free(p2);
// 必须先释放行数组
for (size_t i = 0; i < n; i++) {
free(p3[i]);
}
free(p3);
return (0);
}